


The Datasets
Living datasets backed by automated experiments and open source methods.
OPEN DATASETS INITIATIVE IN DETAIL
Machine learning models are only as good as the datasets they are trained on.
So the question is not “how to make the next AlphaFold,” but rather “how do we make the next Protein Data Bank?” The Open Datasets Initiative creates new, high-fidelity datasets for biological machine learning models.
The problems with existing datasets

How our datasets solve this problem
Our datasets are massive, living, and open. We produce millions of datapoints per dataset, continue growing our datasets over time, and make them publicly accessible along with their protocols and analysis pipelines.
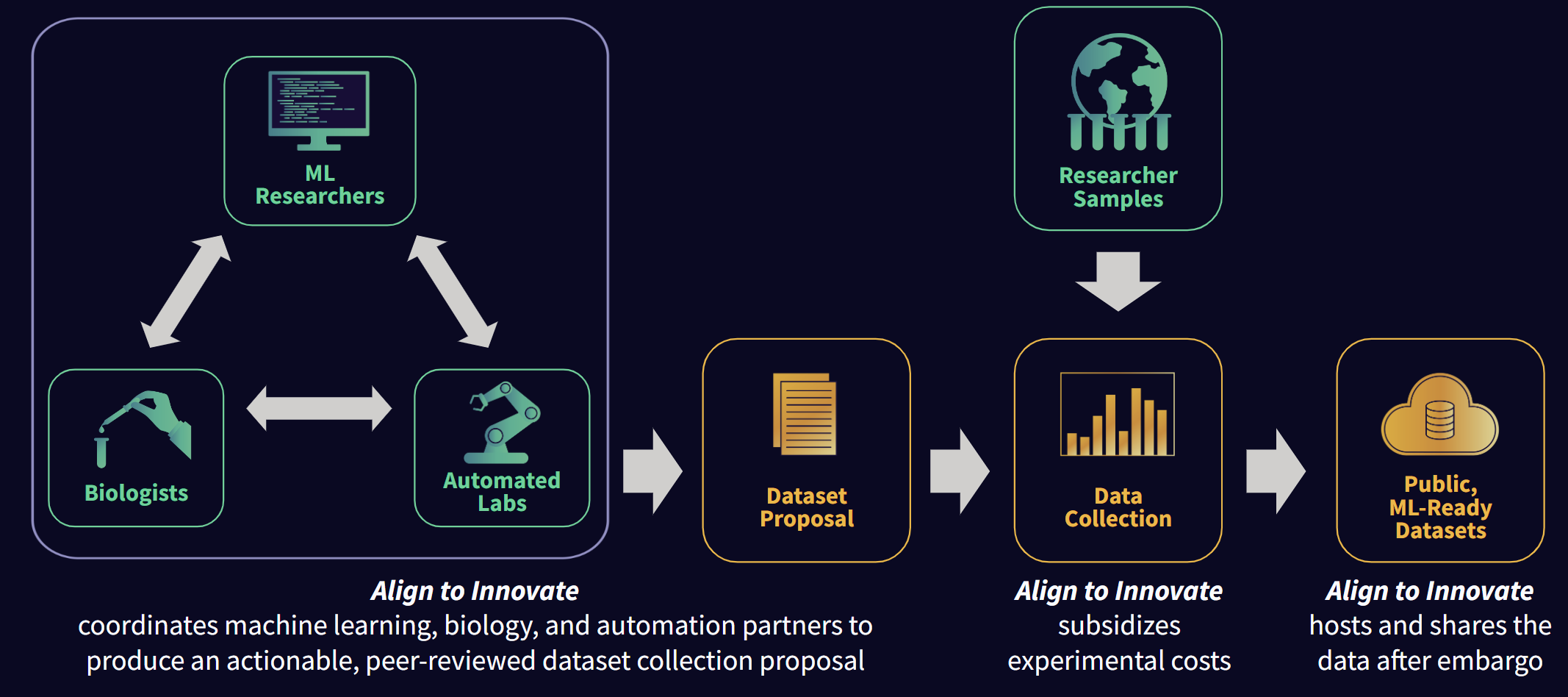
The Dataset Creation Process
-
Our goal is to identify which datasets would be most valuable for life science. Our approach is designed to surface as many ideas as possible and foster discussion between the experimental biology, automation, and machine learning communities.
Conduct interviews and open a call for proposals
Find similarities and consolidate ideas into topic groups
Host workshops to flesh out dataset concepts
Form working groups to shepherd ideas into actionable proposals.
Proposals undergo peer review from experts not involved in developing the proposal to strengthen ideas and select dataset proposals for implementation.
We aim to host an inclusive collaborative process to surface and execute on the best ideas. Everyone who contributes, from submitting a one-sentence idea to working collaboratively to execute a project for multiple years, has their contributions attributed.
If you have an idea for a dataset, submit it HERE.
-
HOW WE ASSESS PROPOSALS
We assess proposals in four topic areas: Significance and Impact, Team, Approach, and additional subject-specific topic areas.
OUR REVIEW PROCESS
Our review process works a bit differently from a standard grant or paper review. While we want reviewers’ feedback about the strengths and weaknesses of each project, we would also like reviewers to add their expertise to strengthen each proposal. Our desired outcome is to advance the strongest proposals to the data collection stage; to do this, we need a full collaboration between all parties, at all stages of development (including review!).
HOW ARE CONTRIBUTIONS ATTRIBUTED?
It takes many hands to make a dataset. Align provides many levels of attribution based on involvement in our Open Datasets Initiative.These categories of attribution will appear on our website, in whitepapers, roadmaps, and other external documents:
Reviewer—provides technical feedback on proposals.
Proposal Leader—leads a dataset working group and/or proposal section.
Working Group member—workshop attendees are part of Ideation Working Groups. Ongoing working groups (e.g., Proposal Working Groups) will also be established to implement selected datasets.
Automation and Data Storage Partner—executes automated, open source methods to generate data. Hosts resultant data for public use.
Sample/Material Provider—scientist who submits samples for analysis and receives data.
Proposal Submitter—submits a well-thought-out proposal for a dataset.
-
We facilitate other people developing the methods by supporting them with project management, subsidizing experimental costs, expert advice, and coordination with collaborators.
We work with automation-enabled research partners to turn methods into executable protocols.
We work with a wide variety of automation providers to scale dataset collection including cloud labs, university biofabs, government facilities, academic labs with robotic equipment, and industry.
-
The “N=N+1 approach”
We engineer for robustness, scalability, and repeatability in order to produce high-quality, living datasets. Many datasets die when a PhD student graduates or a company closes. We are investing in the longevity of the datasets we develop by ensuring that the protocols can be executed at multiple different facilities and do not require the artisanal touch of any single scientist. To do this, we develop every dataset protocol at N=2 different facilities, ensuring the protocols developed are sufficiently general and reproducible to be executed in multiple places. From there, we scale to N+1 facilities.
Our Automation Partners
We currently work with Emerald Cloud Lab, Boston University’s DAMP lab, NIST, the Biodesign Lab at the Francis Crick Institute, and any others that are interested and capable of executing our protocols
Data Collection At Scale
To maximize scalability and create living datasets, our initiative provides funding for scientists worldwide to send in samples for analysis and review experimental data. The same data will also populate a public, shared database after an embargo period to allow researchers time to file provisional patents or publish papers on resulting data. After the embargo period, data will be accessible to the public, which will allow it to be used for both academic and commercial purposes. To learn more about our MTA policy for submitting samples, contact datasets@alignbio.org
-
We believe in the power of Open Science. Our protocols, bioinformatics pipelines, and datasets are publicly available to biologists and machine learning researchers.
Our process is community driven
We collaborate with academic, industry, and government labs to create the proposals and run the experiments. We work with our automation partners to continuously scale dataset collection.
The Open Datasets Initiative provides support to our community of collaborators by subsidizing experimental costs, providing project management, and coordinating collaborations between proposal authors and automation partners. We also manage data hosting and facilitate sharing with the wider scientific community.
ACTIVE DATASET
Protein Sequence to Function

ACTIVE DATASET
Protein Sequence to Expression

ACTIVE DATASET (COMING SOON)
Microbe Genome
to Phenome

LEARN MORE
Datasets in Incubation
Questions? Check out our FAQs page.
Interested in getting involved?
Email us at datasets@alignbio.org
Supported by
A philanthropic initiative founded by Eric and Wendy Schmidt.
A civic engagement initiative by Ken Griffin.